Ajustement des lois de probabilités aux
séries statistiques
Il est bien sûr intéressant de considérer qu’une série statistique obéit approximativement à une loi de probabilité puisque cet amalgame permet de faire toutes sortes de prédictions sur les variables aléatoires associées sans avoir recours à des expérimentations sans fin.
On va donc
prélever, une fois pour toutes, des échantillons assez nombreux de la population à analyser,
essayer de trouver la loi de probabilité qui épouse le mieux la distribution constatée,
contrôler à l’aide du test du c2 (KHI 2) que notre ajustement est judicieux,
et à partir de là, si le test s’avère positif, on pourra dire que la distribution étudiée obéit à la loi l, ce qui nous permettra d’appliquer les résultats des probabilités à un ensemble qui n’est jamais que statistique c'est-à-dire possiblement soumis à des fluctuations au gré des différentes contraintes (plus ou moins connues) qui gouvernent sa distribution réelle.
Ajustement d’une loi binomiale ou d’une loi de Poisson à une série statistique
On va supposer qu’on étudie le comportement d’une machine qui produit quelques pièces défectueuses.
Pour cela, on prélève 100 lots de 100 pièces et dans chaque lot, on compte les pièces défectueuses ce qui nous donne la variable aléatoire x attachée à chaque lot et nX est le nombre de lots dans lesquels on a trouvé x pièces défectueuses.
On obtient les chiffres suivants :
|
X |
nX |
XnX |
|
0 |
2 |
0 |
|
1 |
7 |
7 |
|
2 |
14 |
28 |
|
3 |
21 |
63 |
|
4 |
19 |
76 |
|
5 |
17 |
85 |
|
6 |
11 |
66 |
|
7 |
5 |
35 |
|
8 |
4 |
32 |
|
9+ |
0 |
0 |
|
Total |
100 |
392 |
Et l’on voit qu’en moyenne chaque lot de 100 pièces contient 392 / 100 = 3,92 pièces défectueuses.
![]() = 3,92
= 3,92
D’où l’on pourrait tirer en première approche que la probabilité p pour une pièce d’être défectueuse serait :
p = 0,0392 = 3,92%
Si l’on veut ajuster une loi binomiale à cette série, ce devrait être une loi
B(100 ; 0,0392) ou une loi proche, par exemple B(100 ; 0,03) ou B(100 ; 0,04).
Chaque lot est une série de n = 100 tirages dans lequel on compte le nombre de réalisations d’un évènement (pièce défectueuse) dont la probabilité est proche de p = 0,0392.
La probabilité pour qu’un lot contienne x pièces défectueuses
est P(X = x) =
![]()
Exprimée en pourcentage cette probabilité ou fréquence du nombre de lots avec x pièces défectueuses devrait s’approcher de nx puisque Σ nx = 100. On l’appellera Nx pour signifier qu’il est calculé à l’aide de la loi et le distinguer de nx déterminé par l’expérience.
Par exemple si P(X = x) = 4% c’est que Nx = 4.
Plus l’ajustement de la loi sera judicieux, plus Nx sera , en moyenne, voisin de nx.
Si l’on veut ajuster une loi de Poisson à cette série, on doit d’abord vérifier que le phénomène est rare (c’est la cas avec une probabilité de l’ordre de 4%) et les épreuves nombreuses (n>50). On pourrait aussi vérifier que la moyenne des valeurs est proche de la variance puisque, pour une loi de Poisson, on a E(X) = V (X) = m.
La moyenne des pièces défectueuses par lot devrait approcher m = 3,92. Cette moyenne est aussi le paramètre m de la loi de poisson et la probabilité de trouver x pièces défectueuses dans un lot devrait être :
P(X = x) = 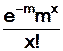 . Et comme P(X = x) =
. Et comme P(X = x) = ![]() . On a NX = 100.
. On a NX = 100. 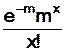
Comparons les valeurs calculées par le biais de différentes lois de probabilités (arrondies) et les valeurs empiriques déterminées par l’expérience.
|
Expérience |
B n=100 p=0,0392 |
B n=100 p=0,03 |
B n=100 p=0,04 |
P m=3,92 |
P m=4 |
|
|
X |
nX |
NX |
NX |
NX |
NX |
NX |
|
0 |
2 |
1,8 |
4,8 |
1,7 |
2 |
1,8 |
|
1 |
7 |
7,5 |
14,7 |
7 |
7,8 |
7,3 |
|
2 |
14 |
15,1 |
22,5 |
14,5 |
15,2 |
14,7 |
|
3 |
21 |
20,1 |
22,7 |
19,7 |
19,9 |
19,5 |
|
4 |
19 |
19,9 |
17,1 |
19,9 |
19,5 |
19,5 |
|
5 |
17 |
15,6 |
10,1 |
16 |
15,3 |
15,6 |
|
6 |
11 |
10,1 |
5 |
10,5 |
10 |
10,4 |
|
7 |
5 |
5,5 |
2 |
5,9 |
5,6 |
6 |
|
8 |
4 |
2,6 |
0,7 |
2,9 |
2,7 |
3 |
|
9+ |
0 |
1,7 |
0,3 |
1,9 |
1,9 |
2,1 |
|
Total |
100 |
100 |
100 |
100 |
100 |
100 |
On voit qu’ « à vue de nez » les lois B(100, 0,0392) , B(100, 0,04) , P(3,92) et P(4) sont dans la course pour revendiquer le meilleur ajustement de la série par une loi.
Le test du c2 départagera les différents postulants.
Test du c2
|
Méthode On répartit les valeurs de l'échantillon (de taille n)
dans k classes distinctes et on calcule les effectifs de ces classes. Si l’on
regroupe certaines classes pour les doter d’un effectif plus important, k
diminue en conséquence. On calcule La statistique Q donne une mesure de l'écart existant entre les effectifs théoriques attendus et ceux observés dans l'échantillon. En effet, plus Q sera grand, plus le désaccord sera important. La coïncidence sera parfaite si Q=0. Le degré de liberté (d) de la variable soumise au test (oi) est obtenu en soustrayant à k le nombre de relations entre les k valeurs qui ont été utilisées dans le paramétrage de la loi de référence. Par exemple si on a une relation de type Σ oi = n (loi B(n,p)) le degré de liberté devient k – 1 Si, de plus on a eu besoin de calculer la moyenne
m des oi pour tester l’adéquation à la loi B(n,p)
(p déduit de m) ou P(m) (m paramètre de la loi de Poisson) le degré de liberté
deviendra k – 2. La table donne, pour d degrés de libertés, une fonction de répartition de Q : la probabilité pour que Q soit plus grand qu’une valeur donnée q. En situant Q dans l’échelle des valeurs de q on sait que Q a entre x% et y% de chances d’être dépassé. Plus la probabilité de Q d’être dépassé est grande, plus l’adéquation de la loi à la série est judicieuse |
|
|
||||||||||||||||||||||||
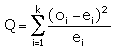
|
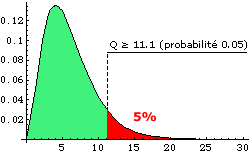
Exemple On a lancé un dé 90 fois et on a obtenu les issues 1 à 6 (k=6) avec les effectifs suivants: 12, 16, 20, 11, 13, 18. Si le dé n'est pas pipé (notre hypothèse), on attend comme effectifs moyens théoriques 15 pour toutes les issues.
Pour k-1=5 degrés de liberté on trouve dans la table Q entre les valeurs
Ce qui signifie que la probabilité pour Q d’être dépassé est un peu supérieure à 50% . L’adéquation de la loi à la série n’est pas fameuse. |
|
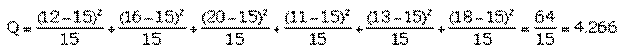
En ce qui nous concerne nous regroupons les lignes à effectif réduit (par exemple les 2 premières et les 3 dernières) pour obtenir un effectif suffisant. Au lieu de 10 valeurs pour x (de 0 à 9) nous n’en avons plus que 6 ou 7 selon nos regroupements. L’effectif minimal pour chaque ligne est de l’ordre de 8.
Pour chacune des
lignes et chaque loi à tester nous calculons 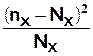
Puis pour chaque loi nous calculons Q = Σ
Nous trouvons :
|
LOi |
Q |
k lignes |
r relations |
degrés k - r |
test |
|
B(100, 0,04) |
0,49 |
7 |
Σ nx = 100 |
6 |
>90% |
|
B(100, 0,03) |
26,88 |
6 |
Σ nx = 100 |
5 |
<1% |
|
B(100 , 0,0392) |
0,38 |
7 |
Σ nx = 100 ; Σ xnx /100 =3,92 |
5 |
>90% |
|
P(4) |
0,69 |
7 |
Σ nx = 100 |
6 |
>90% |
|
P(3,92) |
0,67 |
7 |
Σ nx = 100 ; Σ xnx /100 =3,92 |
5 |
>90% |
Dans chaque ligne :
La loi testée
Le khi – 2 calculé (Q)
Le nombre de classes utilisées dans le calcul (après regroupement des classes les moins nombreuses)
Les relations utilisées dans le paramétrage de la loi et dont il faudra soustraire le nombre à k pour trouver le degré de liberté.
Le degré de liberté
La probabilité de dépasser Q d’après les tables.
On voit que tous nos ajustements sont bons sauf en ce qui concerne la loi B(100 , 0.03)
Cas de
séries multiples
On calcule le khi – 2 (Q) de la même façon.
Si la série figure dans un tableau de dimensions n x p le degré de liberté initial de la variable est
(n – 1) x (p – 1).
On le diminue du nombre de relations nécessaires au calcul des paramètres de la loi.
Ajustement d’une loi normale à une série
statistique.
Ajustement
graphique : droite de Henri
La série a l’allure suivante
|
Poids en kg X |
<45 |
45-47 |
47-49 |
49-51 |
51-53 |
53-55 |
55-57 |
>57 |
total |
|
effectif n |
35 |
53 |
76 |
100 |
88 |
78 |
42 |
28 |
500 |
Nous pouvons calculer la fréquence de chaque classe, puis les fréquences cumulées
|
Poids en kg X |
<45 |
45-47 |
47-49 |
49-51 |
51-53 |
53-55 |
55-57 |
>57 |
total |
|
effectif n |
35 |
53 |
76 |
100 |
88 |
78 |
42 |
28 |
500 |
|
fréquence |
0.07 |
0.106 |
0.152 |
0.2 |
0.176 |
0.156 |
0.084 |
0.056 |
1.00 |
|
x |
45 |
47 |
49 |
51 |
53 |
55 |
57 |
¥ |
|
|
P (X < x) f. cumulée |
0.07 |
0.176 |
0.328 |
0.528 |
0.704 |
0.86 |
0.944 |
1 |
|
Donc on peut lire dans ce tableau qu’empiriquement, on a par exemple : P(X < 53) = 0.704.
Essayons de raccrocher cette série à une loi normale N(m,s) .
Si c’est le cas , en posant T = ![]() , la loi de T
doit être une loi normale, centrée réduite F (t)
, la loi de T
doit être une loi normale, centrée réduite F (t)
Les tables nous disent en fonction de t que P (T < t) = F (t)
ou si on les utilise à l’envers que t = F -1(P) .
Prenons par
exemple P(X < 53) = 0.704
Nous en tirons P (sT+m < 53) = 0.704 ou P (T < ![]() ) = 0.704
) = 0.704
Cherchons sur
la table t = F -1(0.704) et on devrait avoir t = ![]() = 0.54
= 0.54
Plus
généralement F -1(P(X < x) ) = ![]() ou x = s [F -1(P(X < x) )] + m
ou x = s [F -1(P(X < x) )] + m
Donc pour résumer :
P(X < x) est donnée en fonction de x dans notre tableau
y = F -1(P(X < x) est donnée par une lecture inverse de la table de F
Et si notre série est bien ajustable par une loi normale, x et y doivent être liés par une relation affine
x = sy + m. ou y = ![]()
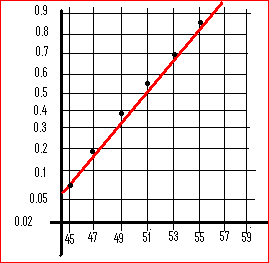
Pour éviter de rechercher sur les tables, on utilise du papier quadrillé gausso – arithmétique qui présente la propriété suivante : Sur l’axe de y , le point d’ordonnée F -1(P) porte la graduation P.
Sur ce papier,
je n’ai donc qu’à situer les points donnés par le tableau, à savoir les
points [ x ,
P(X < x)]
et il s’agit en
réalité des points [x , F -1(P(X < x) ]
Par exemple, sur l’axe des y le point gradué 0,7 sur le papier (pratiquement 0,704) correspond en réalité à t = 0,54
Si notre ajustement par une loi normale est valable, ces points doivent être alignés en une droite appelée « Droite de Henri ».
Comment trouver m grâce à ce
graphique ?
x = m correspond à t = 0 et P(T < 0) = P(X < m) = 0,5.
On voit qu’au point d’ordonnée 0,5 correspond l’abscisse 51 . C’est donc que m = 51.
Comment trouver s grâce à ce graphique ?
On sait que F (1) = 0,84. et comme x = sT + m pour T = 1 cela correspond à x = s + m .
Sur le graphique on voit qu’à l’ordonnée 0,84 correspond l’abscisse x = 55 = s + 51 .
C’est donc que s = 4.
Pour
résumer :
ordonnée 0,5 ® abscisse m
ordonnée 0,84 ® abscisse s + m
Ajustement
analytique d’une loi normale à une série
On garde les anciennes fréquences P(X < x j) x j étant une extrémité de classe
On prend les centres de classes Xi .
On leur affecte l’effectif de la classe ni.
On calcule la moyenne m et l’écart type s des xi
On ajuste une loi N(m , s)
on cherche les variables centrées
réduites t
j = ![]() x j
étant une extrémité de classe
x j
étant une extrémité de classe
on cherche dans la table p j = F (t j) ¾ F(t j-1)
L’effectif théorique de chaque classe est nj = 500 p j
On compare
effectif théorique et effectif pratique.
Le test du khi – 2 nous dira si l’ajustement est valable.