Statistiques : notions de
base
Collecte
et présentation des données
Vocabulaire
Statistique : ensemble de données chiffrées
sur un ensemble nombreux
˜ Population : ensemble sur lequel portent les
statistiques (humains, automobiles,
objets sortant d’une usine)
Individu : élément d’une
population
Caractères : caractéristiques de la
population soumises à l’étude (couleur des yeux, durée de vie,…)
modalités : valeurs que
peut prendre le caractère (caractère sexe : modalités masculin et féminin)
modalité qualitative : modalité non
mesurable comme la couleur des yeux ou le sexe
modalité quantitative : exprimée par
un nombre appelé variable statistique
variable discrète :
prenant des valeurs nettement distinctes les unes des autres
nombre d’enfants d’un couple Î { 0 , 1 , 2, ……, 30}
variable continue : pouvant prendre toutes
les valeurs dans un intervalle donné
Taille en mètres d’un
individu de 20 ans Î [ 0,5 ; 2,5]
Classe : sous ensemble de la population pour
lequel les caractères prennent une modalité donnée
classe
des humains qui ont les yeux verts et les cheveux bruns
classe
des familles qui ont 3 télévisions
classe
des échantillons de fil de fer dont la charge de rupture se situe entre 10 et
15 kg
classe
des élèves qui ont obtenu la note 12 à un devoir
Effectif : nombre d’éléments d’un ensemble
dénombrable
Effectif global :
nombre total des éléments soumis à l’étude (30 élèves ont passé l’examen)
Effectif d’une classe :
nombre des éléments d’une classe (5 élèves
ont eu la note 12)
Fréquence d’une modalité ou d’une classe :
fraction ou pourcentage que représente l’effectif de la classe par rapport à
l’effectif global. (5 élèves sur 30 (ou
16,66%) ont eu la note 12) .
La fréquence peut aussi être
exprimée par un nombre décimal compris entre 0 et 1: par exemple 16%
= 0,16.
La fréquence (0.) de 12 dans
l’effectif global est 0,16.
Tableaux
et graphiques
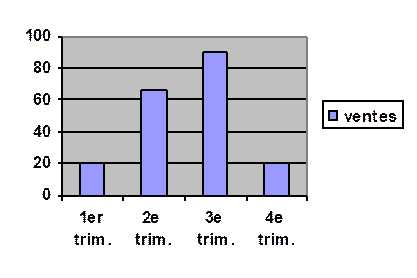
Diagramme en bâtons
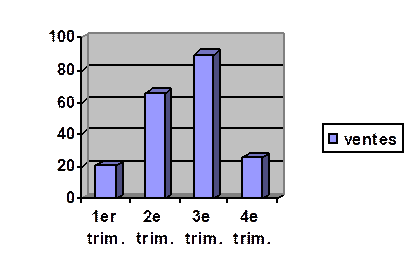
Diagramme à barres
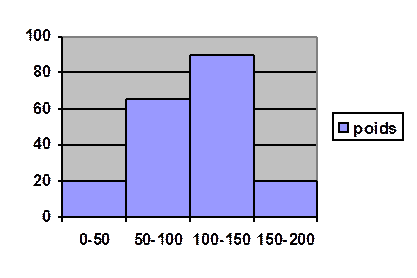
Histogramme
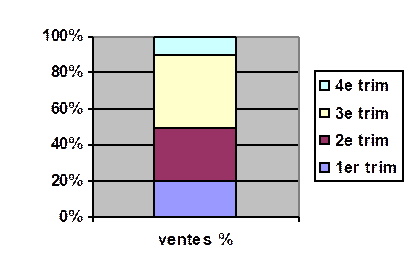
Diagramme à bandes en fréquences
Diagramme à secteurs ou
« fromage »
Etude
des séries statistiques simples
L’effectif
global de la population soumise à l’étude est N
Le caractère
étudié est unique.
La modalité est quantitative
(variable numérique qui prend les valeurs X1 , X2 ,
…..Xt).
En tout t valeurs qui peuvent
être discrètes ou groupées.
Cela signifie que pour le caractère étudié
on a déterminé t classes recouvrant
la totalité de l’effectif.
Dans la classe
numéro i ,
le caractère étudié prend la valeur Xi
Ces
valeurs peuvent être discrètes :
X1 = 12 , X2
= 15 … Dans la classe 1 : X =
12 Dans la classe 2 : X = 15 ….
Ou constituer des intervalles de valeurs
continues :
Dans la classe 1 X
varie entre 0 et 15 , Dans la classe 2 X varie entre 15 et 30 ……….
L’effectif de
la classe i est Ni
On a compté N1 éléments pour lesquels X
= X1
N2 éléments pour
lesquels X = X2
La fréquence
(0.) de la classe i est fi = ![]() .
Pour avoir la fréquence en % : Fi
= fi x 100
.
Pour avoir la fréquence en % : Fi
= fi x 100
On peut donc constituer le tableau suivant
|
Classe |
1 |
2 |
…… |
t |
TOTAL |
|
Valeur du caractère X |
X1 |
X2 |
…… |
Xt |
|
|
Effectif de la classe |
N1 |
N2 |
……. |
Nt |
N |
|
Fréquence (0.) de la classe |
f1 |
f2 |
……. |
ft |
1 |
|
Fréquence (%) de la classe |
F1 |
F2 |
……. |
Ft |
100 % |
|
X enfants |
0 |
1 |
2 |
3 |
4+ |
total |
|
N couples |
50 |
40 |
20 |
10 |
8 |
128 |
|
fréquence |
0.39 |
0.31 |
0.16 |
0.08 |
0.06 |
1 |
Moyenne
arithmétique
Si la variable mesurée est X sa moyenne est notée
![]() .
.
L’effectif global étant N , on a effectué
N mesures de X (ou prélevé N valeurs
de X) qu’on peut regrouper en t classes pour lesquelles on a trouvé
la même valeur de X .
La classe numéro i a un effectif Ni
et dans cette classe la valeur de X
est Xi
Dans une classe i la somme des mesures effectuées est NiXi
La somme totale des N mesures effectuées est donc ![]()
Par définition
La moyenne ![]() est une valeur telle qu’en la multipliant par N je trouve la somme des mesures
effectuées pour X sur toute la population : N
est une valeur telle qu’en la multipliant par N je trouve la somme des mesures
effectuées pour X sur toute la population : N![]() = åNiXi.
= åNiXi.
Il revient au même de dire
que si pour chacun de N individus de
la population, la valeur de X était ![]() , la somme de toutes les valeurs mesurées
pour X ne changerait pas.
, la somme de toutes les valeurs mesurées
pour X ne changerait pas.
On a donc par
définition :
 =
å (Xi
=
å (Xi ![]() )
= å (Xi fi ) = å (Xi
)
= å (Xi fi ) = å (Xi ![]() )
)
On peut exprimer la moyenne
en fonction de l’effectif Ni des classes ou en fonction de leur fréquence.
|
X enfants |
0 |
1 |
2 |
3 |
4 |
total |
|
N couples |
50 |
40 |
20 |
10 |
8 |
128 |
|
fréquence |
0.39 |
0.31 |
0.16 |
0.08 |
0.06 |
1 |
Moyenne = ![]() 1,11
1,11
Si les classes correspondent
à un intervalle de valeurs (valeurs groupées) ?
Soit on connaît la moyenne de
chaque classe et on prend Xi = cette moyenne
Soit on ne la connaît pas et
on prend pour Xi la moyenne des 2 bornes
de l’intervalle (le centre de classe)
Par exemple pour X entre 30 et 40 on prend Xi = 35.
Le mode
ou classe modale :
C’est la valeur que la
variable statistique X prend le plus
fréquemment.
Quand la variable est
discrète et les valeurs non groupées le mode est le Xi de la classe qui a le plus grand effectif.
|
X enfants |
0 |
1 |
2 |
3 |
4+ |
total |
|
N couples |
50 |
40 |
20 |
10 |
8 |
128 |
|
fréquence |
0.39 |
0.31 |
0.16 |
0.08 |
0.06 |
1 |
Mode 0
Mais quand les valeurs sont
groupées, la
classe modale est celle qui a le plus grand effectif par unité de
largeur de la plage couverte par la variable.
Par exemple soit une
population partitionnée en 2 classes :
une classe 1 où X varie de
10 à 12 (largeur 2) avec un effectif de 20 (effectif 10 par unité de largeur)
une classe 2 où X varie de 13 à 16 (largeur 3) pour
un effectif de 27 (effectif 9 par unité de largeur) .
La classe 1 est la classe
modale bien que l’effectif soit plus important dans la classe 2 .
Effectifs
ou fréquence cumulée.
On range les classes par
valeur croissante ou décroissante de X .
Puis pour chaque valeur Xi de
X on se pose les questions suivantes
Quel est l’effectif pour
lequel X < Xi ? On le note N(X < Xi) et il correspond à une
fréquence F(X < Xi)
Quel est l’effectif pour
lequel X > Xi ? On le note N(X > Xi) et il correspond à une
fréquence F(X > Xi)
On parle d’effectifs ou de
fréquences cumulés, « moins de … » ou
« plus de …. ».
|
X enfants |
0 |
1 |
2 |
3 |
4 |
total |
|
N couples |
50 |
40 |
20 |
10 |
8 |
128 |
|
fréquence |
0.39 |
0.31 |
0.16 |
0.08 |
0.06 |
1 |
|
N (X < Xi) |
0 |
40 |
90 |
110 |
120 |
|
|
F (X < Xi) |
0 |
0.39 |
0.70 |
0,86 |
0,94 |
|
|
N(X > Xi) |
78 |
38 |
18 |
8 |
0 |
|
|
F(X < Xi) |
0,61 |
0,30 |
0,14 |
0,06 |
0 |
|
On peut aussi définir le
cumul par N (X ≤ Xi) ou F(X ≥
Xi) par exemple .
La
médiane
C’est la valeur Xi pour
laquelle ni N(X < Xi) ni N(X > Xi) ne sont supérieurs à la moitié de l’effectif.
Moins de la moitié de
l’effectif a un Xi supérieur ou
inférieur à la médiane.
|
X enfants |
0 |
1 |
2 |
3 |
4 |
total |
|
N couples |
50 |
40 |
20 |
10 |
8 |
128 |
|
fréquence |
0.39 |
0.31 |
0.16 |
0.08 |
0.06 |
1 |
|
N (X < Xi) |
0 |
40 |
90 |
110 |
120 |
|
|
N(X > Xi) |
78 |
38 |
18 |
8 |
0 |
|
Médiane = 1 car N(X > 1) = 38 et N (X < 1) = 40
les deux étant inférieurs à 128/2 = 64 .
Autrement dit si on numérote
tous les individus de 1 à N par X croissant
(ou décroissant) , la médiane est le Xi de l’individu
numéroté N/2 si N est pair ou (N+1) / 2 si N est impair.
Médiane = 1 car
si l’on numérote les individus de 1 à 128 de telle façon que leur numéro
croisse avec leur Xi, l’individu no 64 (sur 128) appartiendra à la
classe pour laquelle Xi = 1 .
Dispersion
|
X série 1 |
98 |
99 |
100 |
101 |
102 |
|
N série 1 |
1 |
1 |
1 |
1 |
1 |
|
X série 2 |
80 |
90 |
100 |
110 |
120 |
|
N série 2 |
1 |
1 |
1 |
1 |
1 |
Série 1 : moyenne 100 , médiane 100
Série 2 : moyenne 100, médiane 100
Ces 2 séries ont même médiane
et même moyenne mais la seconde (amplitude de variation de X = 120 – 80 = 40 ) est beaucoup plus dispersée que la première (amplitude
de variation de X = 102 – 98 = 4) .
Ecart
absolu moyen
On mesure les écarts de
chaque valeur Xi de la série à la
moyenne : il s’agit de Xi
– ![]()
|
X série 1 |
98 |
99 |
100 |
101 |
102 |
|
N série 1 |
1 |
1 |
1 |
1 |
1 |
|
Xi – |
–2 |
–1 |
0 |
+1 |
+2 |
|
X série 2 |
80 |
90 |
100 |
110 |
120 |
|
N série 2 |
1 |
1 |
1 |
1 |
1 |
|
Xi – |
–20 |
–10 |
0 |
+10 |
+20 |
Si l’on prenait la moyenne
arithmétique de ces écarts on trouverait 0 ce qui ne rendrait pas compte de la dispersion . Aussi on fait la moyenne des valeurs absolues | Xi – ![]() | de ces écarts :
| de ces écarts :
C’est l’écart absolu moyen. 
Série 1 : ![]()
Série 2 : ![]()
On trouve un écart absolu
moyen 10 fois plus fort pour la 2e série, ce à quoi on pouvait
s’attendre.
Variance et Ecart type.
Plutôt que prendre les
valeurs absolues, pour rendre compte de la dispersion, on élève les écarts à la
moyenne aux carré ce qui supprime l’effet du signe .
La variance est la moyenne
des carrés des écarts à la moyenne :
Variance : 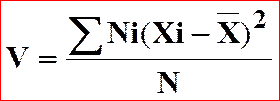
Et pour gommer un peu l’effet
du carré, on définit l’écart type qui est la racine carrée de la
variance :
Ecart type 
|
X série 1 |
98 |
99 |
100 |
101 |
102 |
|
N série 1 |
1 |
1 |
1 |
1 |
1 |
|
Xi – |
–2 |
–1 |
0 |
+1 |
+2 |
|
(Xi – |
4 |
1 |
0 |
1 |
4 |
|
X série 2 |
80 |
90 |
100 |
110 |
120 |
|
N série 2 |
1 |
1 |
1 |
1 |
1 |
|
Xi – |
–20 |
–10 |
0 |
+10 |
+20 |
|
(Xi – |
400 |
100 |
0 |
100 |
400 |
Série 1 : V = 2 s =![]() =
1,4 (e = 1,2)
=
1,4 (e = 1,2)
Série 2 : V = 200 s =![]() =
14 (e = 12)
=
14 (e = 12)
Au contraire de l’écart
absolu moyen, la variance et l’écart type sont très utilisés en statistique
pour rendre compte de la dispersion d’une série.
Théorème de Koenig :
Dans le calcul de la
variance :
On peut remplacer (Xi – ![]() )2 par Xi2
-2Xi
)2 par Xi2
-2Xi![]() +
+![]() 2
2
Au dénominateur on a donc å Ni (Xi2 -2Xi![]() +
+![]() 2)
2)
= å NiXi2 – å2![]() NiXi +
NiXi + ![]() 2åNi
2åNi
= å NiXi2 – 2![]() åNiXi +
åNiXi + ![]() 2N
2N
et comme å NiXi = N![]()
= å NiXi2 – N![]() 2.
2.
Donc V = 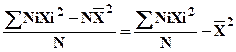
|
V = moyenne des carrés – carré de la moyenne |
Ce qui simplifie en général
le calcul de la variance et de l’écart type
Position
Quartiles
,
déciles, centiles
L’effectif cumulé maximum est
N .
En cumulant l’effectif des
classes å Ni dans le sens des
X croissants ,
il arrive un moment où je franchis le seuil correspondant à une fraction donnée
de la population N / k (k
fractionnaire). Ce franchissement se produit dans une classe et à cette classe
correspond une valeur de X dont le
nom dépend du seuil franchi . Voici :
Le seuil franchi
Le nom de la variable de la classe correspondante
N/4 2N/4 3N/4 1er
, 2e , 3e quartiles (au 2e correspond la médiane)
N/10 2N/10
… 9N/10 1er
, 2e , …., 9e
déciles
(au 5e correspond la médiane)
N/100 2N/100 ..
99N/100 1er , 2e , …, 99e centiles (au 50e correspond la
médiane)
Par exemple, la valeur de la variable X dans la
classe dont l’effectif, en le cumulant à l’effectif des classes de X inférieur franchit la ligne des 8N/10 (huit dixièmes de l’effectif global) est appelée 8e décile.
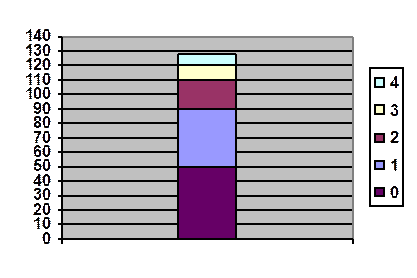
Nombre d’enfants, effectifs cumulés
On a interrogé N = 128 couples pour savoir leur nombre
d’enfants.
En ordonnée on a porté
l’effectif cumulé. Sur ce diagramme, on voit comment chacune des 5 classes
contribue au cumul. A chaque classe correspond une couleur et la légende donne
le nombre d’enfants correspondant.
La médiane est le nombre
d’enfants de la classe contenant le point d’ordonnée N/2 soit 64.
Ce point appartient à la
classe bleue dont le nombre d’enfants est 1
(X = 1) .
Donc la médiane est 1
.
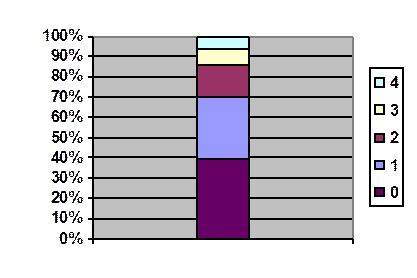
Nombre
d’enfants déciles
Cette fois on a porté en
ordonnée le pourcentage de l’effectif
cumulé.
Ainsi, les graduations de 10%
en 10% correspondant aux déciles.
Le décile est la valeur de la
variable « X enfants » dans la classe contenant la fraction exacte de
l’effectif global recherchée (par exemple 50% pour le 5e décile
tombe dans la zone bleue où X = 1. Le 5e décile est 1).
1er décile 10% = 0
enfant
2e décile 20% = 0 enfant
3e décile 30% = 0 enfant
4e décile 40% = 1
enfant
5e décile 50% = 1
enfant
6e décile 60% = 1
enfant
7e décile 70% = 2
enfants
8e décile 80% = 2
enfants
9e décile 90% = 3
enfants
Il faudrait diviser en
centiles (10 fois plus de graduations)
pour que le nombre 4 apparaisse aux alentours du centile 96.
Si les seules graduations
apparaissant sur le graphique étaient 25%, 50%, 75% elles correspondraient aux
quartiles.
Etude
des séries statistiques doubles
On peut étudier une
population non pas selon un caractère comme nous venons de le faire mais selon n caractères.
Dans ce qui suit nous nous bornerons
à 2 caractères ce qui donne une série statistique double.
Par exemple on peut examiner
une population humaine sous l’angle de la couleur des yeux et de la teinte des
cheveux.
On peut étudier une
corrélation entre le poids et la consommation quotidienne de calories. Entre la
période de rotation des planètes autour du soleil et leur distance à celui-ci.
Nous appellerons le 1er
caractère X et pour un individu donné il pourra prendre
les valeurs X1, X2 , ..Xn
Nous appellerons le 2e caractère Y et pour un individu donné
il pourra prendre les valeurs Y1, Y2 , ..Yp.
Ce qui fait qu’il y a np combinaisons
possibles pour les 2 caractères et donc en théorie np classes élémentaires différentes d’individus (certaines pouvant
être vides).
Bien sûr, il est impossible
qu’un individu appartienne à plusieurs classes élémentaires.
Nous appellerons Cij la classe correspondant à X = Xi et Y = Yj et nous noterons son effectif Nij
On a ![]() effectif global ce que l’on peut aussi noter
effectif global ce que l’on peut aussi noter ![]()
Les séries doubles sont présentées dans des tableaux
à double entrée lorsque les variables sont discrètes ou groupées:
|
X Y |
X1 |
X2 |
… |
Xn |
|
Y1 |
N11 |
N21 |
|
Nn1 |
|
Y2 |
N12 |
N22 |
|
Nn2 |
|
…. |
|
|
|
|
|
Yp |
N1p |
N2p |
|
Nnp |
Mais on peut aussi définir
des classes non élémentaires par regroupement, par exemple la classe pour
laquelle X = X1 (indépendamment de Y). L’effectif de cette nouvelle classe est
le cumul de l’effectif des classes pour lesquelles X = X1 (colonne X1 du tableau) .
Quand les variables sont continues et (ou) qu’on
prélève n échantillons au hasard pour tenter de voir si une loi mathématique
lie X et Y , on utilise un tableau à 2 lignes ou 2
colonnes :
|
X |
0,5 |
1 |
1,5 |
2 |
2,5 |
3 |
3,5 |
4 |
4,5 |
5 |
|
Y |
1,2 |
3,2 |
4 |
6 |
8,3 |
9,1 |
10,9 |
12,4 |
13,1 |
15,3 |
C’est plutôt à ce type de
série double que nous allons nous intéresser maintenant
Ajustements,
corrélations
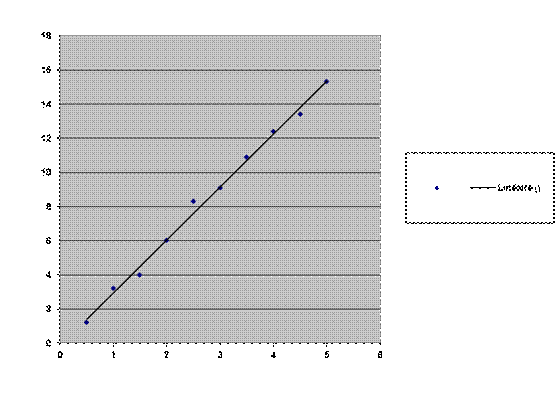
Si nous plaçons les points de
la série précédente dans un repère cartésien, il semble qu’ils s’alignent à peu
prés ce qui suggère qu’il pourrait y avoir entre Y et X une relation de type Y
=aX ou Y = aX+b
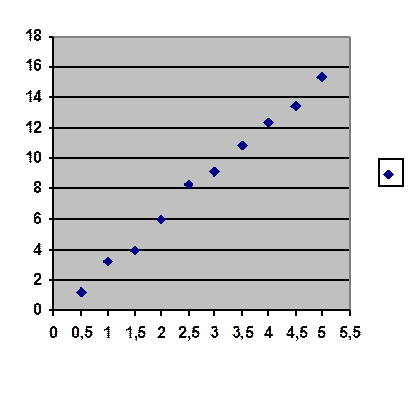
Tout le problème est de
savoir
1) S’il est judicieux de voir
une droite d’équation Y = aX + b dans ce
graphique ?
2) Si c’est le cas, comment
faire pour déterminer a et b les paramètres qui caractérisent la droite ?
Le
test de corrélation linéaire
Covariance
Il s’appuie sur le calcul de
la covariance
de X et de Y qui est définie par
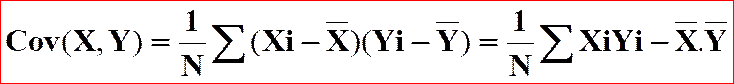
La covariance est à une série
double ce que la variance est à une série simple.
D’ailleurs si dans la formule
on fait X = Y, on retrouve la formule de la variance.
En ce qui concerne notre
série on a
|
X |
0,5 |
1 |
1,5 |
2 |
2,5 |
3 |
3,5 |
4 |
4,5 |
5 |
|
|
Y |
1,2 |
3,2 |
4 |
6 |
8,3 |
9,1 |
10,9 |
12,4 |
13,4 |
15,3 |
|
|
XiYi |
0,6 |
3,2 |
6 |
12 |
20,75 |
27,3 |
38,15 |
49,6 |
60,3 |
76,5 |
å = 294.4 |
Cov (X, Y) = 29.44 – 23,045 = 6.395
Coefficient
de corrélation linéaire
La covariance va maintenant
servir au calcul du coefficient de corrélation linéaire r défini par
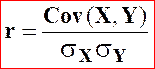
Nous avons donc besoin des
écarts types de X et de Y (sX
et sY )
|
X |
0,5 |
1 |
1,5 |
2 |
2,5 |
3 |
3,5 |
4 |
4,5 |
5 |
|
|
X2 |
0,25 |
1 |
2,25 |
4 |
6,25 |
9 |
12,25 |
16 |
20,25 |
25 |
å= 96.25 |
|
Y |
1,2 |
3,2 |
4 |
6 |
8,3 |
9,1 |
10,9 |
12,4 |
13,4 |
15,3 |
|
|
Y2 |
1,44 |
10,24 |
16 |
36 |
68,89 |
82,81 |
118,81 |
153,76 |
179,56 |
234,09 |
å= 901,6 |
sX = ![]() sY =
sY = ![]() 4,4649
4,4649
sX sY = 6.411
r = ![]() = 0.997
= 0.997
|
r doit être compris entre –1 et +1 Plus r est proche de 1 (droite avec a > 0) ou de –1 (droite avec a < 0) plus Y
et X ont des chances d’être
liés par une relation de type Y = aX +b (a et b constantes, b
peut être nul). Plus r est proche de 0 moins X et Y ont des chances
d’être liés par une relation de type Y
= aX + b. On considère que l’approximation d’une série double par une relation
de type linéaire ou affine est acceptable pour 0,7
< |r | ≤ 1 bonne pour 0,95 < |r | ≤ 1. Dans notre exemple on peut dire qu’elle est excellente. |
La
méthode des moindres carrés
Il s’agit maintenant de
définir la droite y = aX + b qui épouse le mieux la série de points que nous avons situés
dans le repère cartésien.
y est
le y estimé tandis que Y est le y observé.
| Yi – yi |= |
Yi – aXi – b | représente la distance di
entre le point expérimental (Xi , Yi) et le
point de la droite qui a l’abscisse Xi
.
Pur s’affranchir du signe et
des valeurs absolues, on élève au carré et on considère que å di2 doit être minimum
S = å ( Yi – aXi – b )2 qui est une fonction de a et de b variables doit être minimum
S = å (Yi2 + a2Xi2 + b2
–2aYiXi –2bYi + 2abXi) = åYi2 + a2åXi2
+Nb2 –2aå(XiYi) -2båYi +2abåXi
Toutes les sommes et N sont
connus d’après la série.
[Dans notre exemple
S = 901.6 + 96,25a2
+ 10b2 – 2(294,4)a –2(8,38)b +2(2,75)ab
doit être minimum]
On considère d’abord S comme un trinôme en b : mb2
+nb+p (m , n et p étant fonctions de a)
et on trouve qu’il doit être minimum pour
|
b = |
Ensuite b
étant déterminé, on considère S
comme un trinôme en a et on trouve qu’il est minimum pour
On trouve a = 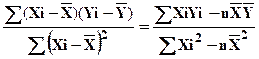
et en divisant par n dénominateur et numérateur
![]()
Dans notre exemple
a = ![]() =3,10
=3,10
b = 8,38 –
(3,10)2,75 = 0,14
L’équation de droite trouvée
est donc y = 3,1x + 0,14
En réalité nous nous sommes vaguement
appuyés sur la droite y = 3X mais il
est probable que la droite trouvée est plus proche en moyenne de notre série de
points que la droite y = 3x.
Contrôle :
l’autre droite
Dans notre exemple, nous
avons supposé les valeurs de X fiables et nous avons ajusté les valeurs de Y .
Nous devons maintenant faire
le contraire et essayer de trouver la droite d’équation x = a’Y +b’ qui se rapproche le plus de nos points
On a
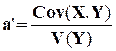
b’ = ![]() –
a’
–
a’![]()
Dans notre exemple
a’ = ![]() = 0.32
= 0.32
b’ = 2,75 – (0.32)8.38 = 0,06
On passe bien
approximativement de y = 3x à x = ![]()
En théorie en cas de relation
linéaire ou affine on devrait avoir a’ = ![]()
Et comme on démontre
facilement que
|
r2 = a.a’ |
Cela explique que r doit être
proche de 1 si l’approximation par une droite est bonne.
Cas des
données groupées
|
X Y |
X1 |
X2 |
… |
Xn |
|
Y1 |
N11 |
N21 |
|
Nn1 |
|
Y2 |
N12 |
N22 |
|
Nn2 |
|
…. |
|
|
|
|
|
Yp |
N1p |
N2p |
|
Nnp |
On peut sans problème
considérer chaque variable indépendamment et calculer par exemple la moyenne,
la variance ou l’écart type de X (ou de
Y) .
On peut aussi calculer ligne
par ligne la moyenne des X pour Y donné qu’on appelle moyenne
conditionnelle de X pour Y donné qu’on note ![]() Y
et tracer la courbe
de régression de X en Y (Yi ,
Y
et tracer la courbe
de régression de X en Y (Yi ,![]() Y)
Y)
On procède aussi par colonne,
on calcule les moyennes conditionnelles ![]() X et on peut tracer la courbe de régression de Y
en X (Xi,
X et on peut tracer la courbe de régression de Y
en X (Xi, ![]() X)
X)
Ensuite on peut
éventuellement chercher une approximation linéaire.
Ajustements
non linéaires
Si l’on soupçonne que Y = a Ln X par exemple on peut toujours
pratiquer le changement de variable
Z = Ln X
Et on peut procéder à un ajustement
linéaire sur la série double Y, Z
après avoir calculé la série Z .
En effet ,
on devrait avoir Y = a Z (relation
linéaire) .