Echantillonnage
Estimation
Rappels Notions à
maîtriser avant l’étude de ce chapitre
X est une
variable aléatoire mesurée au cours de N
tirages et au bout de N tirages on calcule
la moyenne ![]()
Si dans la population m est la moyenne de X et s son écart type.
Pour la moyenne de
l’échantillon considérée comme variable aléatoire on a :
E(![]() ) = m V(
) = m V(![]() )=
)= ![]() écart type de
écart type de ![]() =
= ![]()
X est le
nombre de personnes possédant un caractère l sur N tirages
et au bout de N tirages on évalue la
fréquence (ou proportion) f
= X / N du caractère l
Si
N assez grand E(X) = Np , V(X) = Npq (avec q = 1— p )
Pour
la fréquence f de l considérée comme
variable aléatoire on a :
E(f) = p et V(f) = ![]() écart type de f
=
écart type de f
=
![]() (tirages avec
remise)
(tirages avec
remise)
Considérations
générales
Lorsqu’on veut recueillir des
informations sur une population statistique, on procède par sondage
dés lors que la méthode exhaustive ou recensement n’est pas appropriée (pour des
raisons qui peuvent être diverses).
Pour procéder à un sondage on
doit
1) prélever un échantillon de
la population c’est la phase d’échantillonnage.
2) déduire de cet échantillon
les caractéristiques chiffrées probables de la population, c’est la phase de l’estimation.
Les problèmes qui se posent
autour de l’échantillonnage sont le choix de la taille de l’échantillon et le choix de la
méthode d’échantillonnage qui doit à la fois respecter autant que
possible le hasard pur et bien sûr composer avec les contraintes
contextuelles. L’échantillon est dit
« représentatif »
lorsqu’on pense que l’on peut sans risque étendre les conclusions qu’il rend à
l’ensemble de la population.
L’estimation, elle, ne peut
déboucher sur une certitude. Elle va formuler ses conclusions dans une phrase
qui ressemble à ça : « avec un risque de 5% on peut dire que le pourcentage de la population possédant un
caractère l se situe entre
18% et 22% »
Donc, une estimation produit
toujours deux données chiffrées : le risque (5%),
qui mesure la fiabilité du sondage et l’intervalle de confiance ( [18% ; 22%] ) qui traduit la précision du sondage.
Toute estimation qui ne rend
pas compte du risque et des doutes qui
lui sont inhérents est une mauvaise estimation.
En fait les caractéristiques
de l’échantillonnage et l’utilité de l’estimation sont intimement liées.
Il est bien évident, par
exemple, que l’augmentation de la taille de l’échantillon prélevé va à la fois
réduire le risque et l’amplitude de l’intervalle de confiance.
Pour s’en convaincre, il
suffit de remarquer que les échantillons de N pièces prélevés dans une population nombreuse où l’on trouve le
caractère l avec une fréquence p obéissent à la loi binomiale (des tirages exhaustifs dans une
population nombreuse équivalent à des tirages avec
remise).
Si X est le nombre
d’individus possédant le caractère l dans l’échantillon on a : P(X=n)
= ![]()
Par exemple si p = 1/6 = 0,1666 = 16,66% et qu’on prélève des échantillons de taille 10 On aura
X = 0 pour 16% des
échantillons
X = 1 pour 32% des
échantillons
X = 2 pour 29% des échantillons
X = 3 ou + pour 23% des
échantillons
En supposant que les
échantillons prélevés respectent exactement ces proportions on pourrait
dire qu’il y a 61% de chances (32+29) pour que la fréquence de l soit entre 1 sur 10 et 2 sur 10. ( 0,1 < P(l) < 0.2 risque de 39%)
Si je prélevais des
échantillons de taille 100, je devrais en trouver un maximum pour X = 16 et X =
17 et le produit de la précision de l’encadrement de P(l) (0,16<P(l) < 0,17 ici
0,01) par le risque (r%) aura diminué, ce qui signifie que l’estimation sera
meilleure.
Mais en fait ce n’est pas
comme cela qu’on procède : on tire un échantillon et un seul au hasard, on
mesure la fréquence de l dans cet échantillon et
on en déduit que p1% £ P(l) £ p2% avec un risque de r%.
Pour donner un exemple :
N = 12 X = 2 ® au risque de 5% on a 3% £ P £ 52% (valeur réelle 16,6%)
N = 120 X = 20 ® au risque de 5% on a 10% £ P £ 23% (valeur réelle 16,6%)
N = 2000 X = 333 ® au risque de 5% on a 15% £ P £ 17% (valeur réelle 16,6%)
Méthodes
d’échantillonnage
˜ Tirages au
hasard
On numérote la population, on
tire des nombres au hasard, on prélève l’échantillon de population
correspondant aux nombres tirés.
Sondage
systématique
On détermine la taille N de
l’échantillon et on prélève systématiquement 1 individu sur n jusqu’à atteindre
le chiffre N .
Sondage par
grappes
On prélève des grappes
d’individus localisés au même endroit ce qui diminue le coût
Sondage
avec probabilités inégales
S'il existe, au tirage, des disparités entre individus, on affecte
les individus ayant la probabilité p d’être tirés d’un coefficient (un
poids) 1/p
Sondage à
plusieurs degrés
Par exemple on constitue des
groupes au hasard puis on tire au hasard dans chaque groupe.
Coût et précision diminués.
Méthode des
quotas
A partir d’informations
antérieures, on construit un échantillon aussi représentatif que possible de la
population ce qui signifie que les quotas de certains caractères jugés en
corrélation avec la caractéristique étudiée sont respectés.
( Par exemple 1000 hommes 900 femmes 700 ouvriers 400 25 –
35 ans ...). C’est une méthode souple et de faible coût donc souvent utilisée
mais échappant aux règles de probabilités du fait qu’elle néglige le hasard. on ne connaît ni la précision ni la fiabilité des
estimations tirées de ce procédé.
Sondage
stratifié
Lorsqu’on connaît précisément
certaines caractéristiques de la population on peut constituer des groupes homogènes
selon ces critères (strates) et on tire indépendamment un échantillon aléatoire
dans chaque strate. Gain de précision par rapport aux autres méthodes utilisant
les groupements.
Distribution
d’échantillonnage
Il s’agit de déterminer les
caractéristiques approximatives de l’échantillon à partir d’une population
connue.
Population totale d’effectif P
Echantillon prélevé de taille
N.
Tirage avec remise (entre
parenthèses résultats avec tirage exhaustif)
On tire une élément de la population et on observe la
valeur de X .
E(X) = m et V(X) = s2
Moyenne
de l’échantillon
![]() est
la moyenne observée dans l’échantillon, m et s des valeurs réelles dans la population.
est
la moyenne observée dans l’échantillon, m et s des valeurs réelles dans la population.
Soit un échantillon de taille N on a
|
E( |
Lorsque N est
grand (> 30)
|
La loi de Y = |
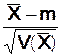
Et les relations P( |Y| < 1,96) = 0,95 et P(
|Y| < 2,58) = 0,99 permettent
de donner un encadrement de ![]() au risque de 5% ou
de 1%.
au risque de 5% ou
de 1%.
Par exemple de - 1,96
< 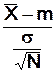 < + 1,96 on tire
< + 1,96 on tire
|
m – 1,96 |
Lorsque N est
faible (< 30)
Si la loi de X est une loi
normale alors la loi de ![]() est une loi normale.
est une loi normale.
On ne peut rien dire de plus.
On
connaît la moyenne et l’écart type vrais . Quel est
selon la taille de l’échantillon l’intervalle de situation de la moyenne observée
(f) au risque de r% ?
Dans une population la
moyenne de X est m = 800 et l’écart type est s = 60 .
Que peut on
dire de la moyenne de X dans un
échantillon de 100 individus ?
E(![]() ) = 800 V(
) = 800 V(![]() ) =
) = ![]() = 36 et Y
=
= 36 et Y
= 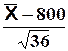 suit une loi N(0,1)
suit une loi N(0,1)
On a donc P( |Y| < 1,96) = 0,95
(extrait des tables de la loi normale)
|Y| < 1,96 s’écrit
– 1,96 < < +1,96 ou – 1,96![]() <
< ![]() – 800 < + 1,96
– 800 < + 1,96![]()
et donc au risque de 5% on a 800 – 1,96![]() <
< ![]() < 800 + 1,96
< 800 + 1,96![]()
On a
donc 95% de chances pour que 788,24 < ![]() < 811,76
< 811,76
On a aussi P( |Y| < 2,58) = 0,99
(extrait des tables de la loi normale)
et donc au risque de 1% on a 800 – 2,58![]() <
< ![]() < 800 + 2,58
< 800 + 2,58![]()
On a
donc 99% de chances pour que 784,52 < ![]() < 815,48
< 815,48
Proportions
Dans la population la fréquence du caractère l est connue P(l) = p
Dans un échantillon de taille N ,
X est le nombre de personnes possédant le caractère l .
X est la somme de N
variables de Bernouilli indépendantes dont la moyenne
est p .
Si N est grand
Loi des grands nombres : si N ® ¥ alors
X/N ® p .
|
E(X) = Np , V(X)
= Npq
(avec q = 1 – p) |
Posons
f = X / N proportion du caractère l dans des échantillons de grande taille.
|
E(f) =
p et V(f) = |
Si N est suffisamment grand
on peut correspondre que
|
f obéit à une loi N ( p , |
Si n n’est
pas assez grand
On utilise la loi binomiale B(N, p) .
On
connaît la proportion vraie (p). Quel est selon la taille de l’échantillon
l’intervalle de situation de la proportion observée (f) au risque de r% ?
il existe des tables donnant
les intervalles de pari d’une proportion à 95%
(ou à 99% ).
Par exemple, pour un pari à
95%, on peut s’appuyer, entre autres, sur une famille de courbes paramétrées
par le nombre d’éléments N de l’échantillon.
Pour chaque valeur de N on a
2 courbes qui ressemblent à celles qu’on voit sur le graphique ci-dessous
(celles – là correspondent à N = 20).
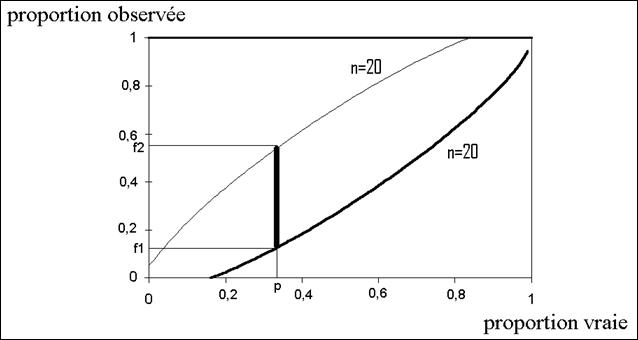
Si la proportion vraie est p , on trace la
droite x = p , elle intercepte le
couple de courbes N = 20 en deux
points d’ordonnée f1 et f2. Et on peut dire qu’au risque de 5% la fréquence f qu’on va mesurer dans une échantillon de 20 éléments sera telle que f1 < f < f2 .
Les courbes de paramètre N = 50 seront situées entre les courbes
N = 20 ce qui fait, qu’au même
risque l’intervalle de confiance rétrécit quand la taille de l’échantillon
augmente.
On
connaît la proportion vraie (p). Quelle est la taille N de l’échantillon qui
permet d’obtenir pour la fréquence observée (f) une précision de e% au risque de r% ?
p = 1/6 (donc q = 5/6)
La fréquence f doit être connue au 50e
prés (e% = 2%) avec une probabilité
de 99% (risque r% = 1%) .
Quelle doit être la taille N de l’échantillon choisi pour
déterminer f ?
f obéit à
une loi N ( p ,
![]() )
)
![]() obéit à une loi
N(0,1)
obéit à une loi
N(0,1)
On a donc –
2,58 < ![]() < +2,58 avec
une probabilité minimale de 0,99 (d’après
les tables)
< +2,58 avec
une probabilité minimale de 0,99 (d’après
les tables)
Ce qu’on peut aussi écrire P ( p – 2,58![]() < f < p + 2,58
< f < p + 2,58![]() ) > 0,99
) > 0,99
Il faut donc 2,58![]() < e% ou 2,58
< e% ou 2,58![]() < 2/100 avec
pq = 5/36
< 2/100 avec
pq = 5/36
ce qui donne N > 2311
Estimation
Estimateurs
On observe N fois la variable
X d’une population.
On trouve les valeurs X1 , X2 , ...., XN
Nous cherchons à connaître
soit la moyenne (Y = ![]() ) soit l’écart type (Y
= s) de X dans
la population totale.
) soit l’écart type (Y
= s) de X dans
la population totale.
Pour cela nous utilisons une
valeur, Z ,
calculée à partir de X1 , X2
, ...., XN
|
On dit que Z est un
estimateur de Y si Z converge en moyenne quadratique
vers Y c'est-à-dire si lorsque N ® ¥ E(Z) ® Y V(Z) ® 0 Si E(Z) =Y l’estimateur
est dit « sans biais » |
cas d’un tirage avec
remise : f est un estimateur
sans biais de la proportion p réelle
dans la population.
Mode de tirage quelconque : E(![]() ) = m (moyenne
réelle de X) .
) = m (moyenne
réelle de X) . ![]() est
un estimateur sans biais de m.
est
un estimateur sans biais de m.
Tirage sans remise : Par contre V(X) n’est pas un estimateur sans biais
de s2 .
Tirage sans remise : ![]() est un estimateur sans
biais de s2.
est un estimateur sans
biais de s2.
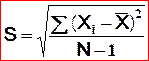 . S et
s équivalents si N est grand
. S et
s équivalents si N est grand
.
Problème : Quelle est la
précision de l’estimation ?
Estimation.
On procède à une estimation
lorsque ayant affaire à une population peu ou mal connue, on cherche à évaluer
certaines de ses caractéristiques (moyenne, proportion, écart type) à
travers les caractéristiques d’un échantillon de taille N.
Estimation
de la moyenne
P population
Si P suit une loi normale ® ![]() moyenne de
l’échantillon suit une loi normale
moyenne de
l’échantillon suit une loi normale
Si P inconnue et N effectif
de l’échantillon > 30 ® ![]() moyenne de
l’échantillon suit une loi normale
moyenne de
l’échantillon suit une loi normale
Si P inconnue et N effectif
de l’échantillon < 30 ® loi de Student avec N – 1 degrés de libertés.
Effectif de l’échantillon N > 30 , s (population) connu
De -1,96 < <+1 ,96
avec une probabilité de 95% on tire
|
|
ce qui donne un encadrement de m au risque de 5%
Effectif de l’échantillon N > 30 , s (population) inconnu
L’écart type s
n’étant pas connu, on en fait une estimation : 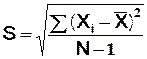
(ou si on
connaît la variance dans l’échantillon : S = 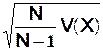 )
)
A partir de là , on procède comme précédemment :
|
|
ce qui donne un
encadrement de m au risque de 5% .
On remplace 1,96 par 2,33
pour un encadrement au risque de 1%.
Effectif de l’échantillon N < 30 , Test de Student
Supposons qu’on veuille un
encadrement de la moyenne au risque de 1%.
On cherche dans la table de Student : la valeur de t qui a 1% de chance d’être dépassé avec N – 1 degrés de liberté est T.
On calcule la moyenne ![]() de l’échantillon.
de l’échantillon.
On estime l’écart type S de la population
Et on écrit l’encadrement au risque de 1% :
|
|
Estimation
d’une proportion
Dans la population la fréquence p du caractère l est inconnue
Dans un échantillon de taille N , X est le nombre de personnes possédant le caractère l
f = X / N est la fréquence observée dans
l’échantillon
Il faut donner une estimation de p.
X suit une
loi binomiale B (N, p)
f suit
une loi parente de la loi binomiale
P ( X = x) = P(f = x/N) donc
E(f) = p et V(f) = ![]() avec p inconnu
avec p inconnu
|
p est
estimé par f (fréquence dans
l’échantillon) V(p) est
estimé soit par soit par Si N > 100 la loi
de p est approchée par une loi
normale N (f ,
|
Pratiquement
Si N est petit
on utilise à l’envers
l’abaque qu’on utilisait pour encadrer la fréquence observée connaissant
la proportion réelle.
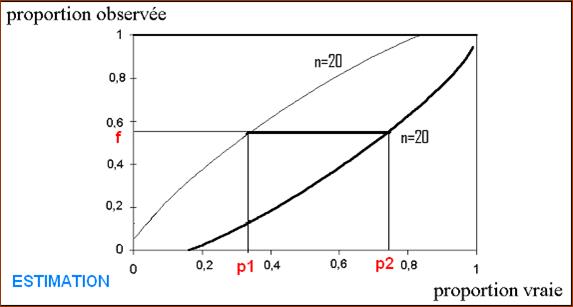
On choisit la famille de
courbes correspondant au risque r%
choisi (5% ou 1% en principe)
Dans cette famille on choisit
le couple de courbes paramétrées par n
le plus proche possible de N (ici n
= 20)
On trace la droite y = f qui coupe le couple de courbes de paramètre n en des points d’abscisse p1 et p2 .
On estime qu’au risque de r% la proportion vraie, p,
vérifie p1 <
p < p2
Si N est grand
On suppose que p est distribué selon une loi normale N (f , 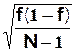 )
)
On calcule s = estimation de l’écart type
Et on écrit par exemple qu’au
risque de 5%
f –
1,96 S < p
< f + 1,96S
Estimation d’un écart type
Ponctuellement
S est estimé
par
s est estimé par
s = 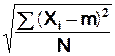 (m de la population
connue) ou
(m de la population
connue) ou 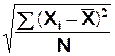 (m inconnue)
(m inconnue)
l’estimateur suit une
loi A
= (n – 1 ) ![]() du c2 à N-1
degrés de libertés
du c2 à N-1
degrés de libertés
1) On calcule a = (n – 1 ) ![]()
2) On cherche pour N – 1 degrés de liberté la probabilité P(A > a) (table du c2 )
3) si on a 0,025 < P(A
> a) < 0,975 on dira qu’on a un intervalle de confiance de 5%
4) Si c2 (0,025) =
a1 et c2 (0,975) =
a2 on peut dire que a1 < A < a2 avec une probabilité
de 5%
5) de a1
< (n – 1 ) ![]() on tire
on tire 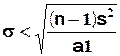
6) de (n – 1 ) ![]() < a2 on tire
< a2 on tire 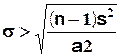
7) et en fin de compte on a
l’encadrement de s suivant au risque de 5% :
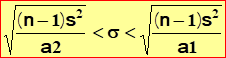
|
Complément Emprunt à WIKIPEDIA Lorsqu'il s'agit d'estimer la dispersion autour de
la moyenne d'un caractère statistique dans une population de grande taille à
partir d'un échantillon de taille n, on utilise pour l'écart type la valeur
suivante
On peut remarquer que
La question que l'on se pose généralement est
« Pourquoi n - 1 ? ». La raison pour laquelle on divise par n
- 1 au lieu de n est un bel exemple de l'interaction permanente entre les
statistiques et les probabilités. Le sondage de n individus correspond à une série de
n variables aléatoires xi indépendantes d'espérance E(X) et de variance V(X).
La moyenne (la moyenne de n variables
aléatoires fluctue moins qu'une seule variable aléatoire). La variance v de l'échantillon est une variable
aléatoire dont on veut calculer l'espérance.
donc égale à E(X)2 + V(X).
est une variable aléatoire d'espérance E(X)2 + V(X).
Donc La variance v de l'échantillon fluctue donc autour
de
et non autour de V(X) comme on aurait pu s'y attendre.
Pour obtenir une estimation de V(X), il est donc
nécessaire de prendre On pourrait dire que v est un estimateur biaisé. Et pour obtenir une estimation de l'écart type
σ(X), il est nécessaire de prendre |
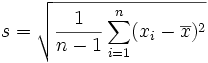
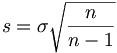
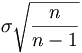
DECISION
STATISTIQUE
Comparaison
d’une moyenne à une norme m0
Une
hypothèse de comparaison de la moyenne m
de la population à une norme m0
est formulée.
Cette hypothèse peut revêtir
plusieurs formes
H0 : peut – on dire
que m
= m0 égalité
H1 : peut on dire
que m
> m0 ou m < m0 majoration minoration
L’hypothèse est forcément
formulée avec un certain risque (en général 5% ou 1%) qu’il nous appartient de
préciser.
On peut à l’inverse avoir le certitude que m =
m0 (ou m > m0 ou m
< m0 ) et se demander si la procédure de
construction de l’échantillon ou les mesures nécessaires à sa constitution sont
valables (là aussi la réponse à cette question est formulée au risque de r%) .
Il y a plusieurs cas de
figures
Ecart type s de la population connu, la population
suit une loi normale ou n > 30
alors ![]() de l’échantillon suit
une loi normale N( m ,
de l’échantillon suit
une loi normale N( m , ![]() )
)
Soit on suppose que m = m0 et on vérifie que ![]() est dans l’intervalle
de confiance au risque donné
est dans l’intervalle
de confiance au risque donné
Soit on formule l’hypothèse
que m > m0 ou m
< m0 et m étant encadré en fonction de ![]() , on regarde où se
trouve m0 par rapport aux bornes de l’encadrement.
, on regarde où se
trouve m0 par rapport aux bornes de l’encadrement.
Ecart type s de la population connu, n < 30
Impossible de conclure sauf si l’on
connaît la loi de la population
Ecart type s de la population inconnu, la population
suit une loi normale ou n>30
On estime s
par
La moyenne suit une loi de
Student à N-1 degrés de libertés.
Si N > 30 la loi de
Student peut être approchée par une loi normale N( m , ![]() )
)
Ecart type s de la population inconnu, n < 30
Impossible de conclure
Exemples :
On mesure N fois une longueur l = l0 (l0
connue) . On connaît l’écart type sur la mesure s
.
Au risque de 5%, les mesures
sont elles réalisées convenablement ?
C’est le cas si l0
– 1,96![]() <
< ![]() < l0 +
1,96
< l0 +
1,96![]()
On mesure 100 fois une valeur X .
On fixe une norme m0 pour ![]() . Peut on dire qu’en moyenne
. Peut on dire qu’en moyenne ![]() ne dépasse pas m0 avec un risque 1% ?
ne dépasse pas m0 avec un risque 1% ?
On ne connaît pas s
de la population mais on l’estime grâce à notre échantillon s = s .
Pour N = 100 on peut
approcher la loi de Student par une loi normale.
On évalue la moyenne ![]() de l’échantillon.
de l’échantillon.
L’hypothèse est acceptable si
![]() < m0 +
2,33
< m0 +
2,33![]()
Comparaison
d’une fréquence à une norme p0
Le problème est le même que
pour une moyenne
Si l’on s’intéresse à la
fréquence p de la modalité l
d’un caractère.
Si X est le nombre d’individus pour lesquels le caractère est l dans
un échantillon de grandeur N .
X suit une
loi binomiale B(N, p0) que l’on approche
par une loi normale dés que N est
assez grand.
Pour ce qui est de f = X / N à la limite sa loi normale est N(p0 , 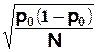
Exemple
N = 100 et X = 12
(f constatée = 0,12).
Peut – on admettre que p = 1/6 au risque de 5%
(comparaison à p0 =
1/6 = 0,17).
Si l’on admet que la
population suit une loi B(100 ; 0,17) on peut l’approcher par la loi normale
N(0,17 ; 0,0395) et au risque de 5% on devrait avoir
0,17 – 1,96(0,0395) < f < 0,17 + 1,96(0,0395)
soit 0,093 < f < 0,24 et comme f = 0,12 l’hypothèse est admissible.
Comparaison
de deux échantillons
Il s’agit de savoir si avec
un risque de r% deux échantillons ont été prélevés dans la même population.
Rappel :
Soit n variables aléatoires Xi
indépendantes chacune suivant une
loi normale d’espérance mathématique mi
et d’écart type si
Σ Xi suit une loi
N(Σ mi ; ![]() )
)
fréquences
1er échantillon effectif N1 , fréquence
mesurée f1
2e échantillon effectif N2 , fréquence
mesurée f2
Si p0 est la
proportion dans la population f d’un l’échantillon issu de la population suit
une loi normale de type N(p0 , )
Soit d =
|f1 – f2| la différence entre les deux fréquences
On estime l’écart type de d par 
Si N1 > 30 et
N2 > 30 on fait l’approximation
normale. d doit suivre une loi N(0 , sd)
Donc si les 2 échantillons
proviennent de la même population, au risque de r% on doit avoir
0 – Dr sd
< d < 0 + Dr sd
(avec par exemple Dr = 1,96
pour r% = 5%)
Moyennes
1er échantillon effectif N1 , moyenne
mesurée m1 , écart type mesuré s1
2e échantillon effectif N2 , moyenne
mesurée m2 , écart type mesuré s2
Si m est la moyenne et s l’écart type dans la population, la moyenne ![]() des échantillons tirés
de cette population suit une loi normale
de type N( m,
des échantillons tirés
de cette population suit une loi normale
de type N( m, ![]() )
)
Soit d =
|m1 – m2| la différence entre les deux moyennes
Si N1 < 30 et N2
< 30 et que les populations d’origines sont distribuées
normalement
On applique une loi de Student à n1 + n2 – 2 degrés de liberté
Si N1 > 30 et
N2 > 30 que les
populations d’origine soient normales ou pas, on fait l’approximation
normale.
|
Sd = |
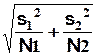
d doit
suivre une loi N(0 , Sd)
Donc si les 2 échantillons
proviennent de la même population, au risque de r% on doit avoir
0 – Dr Sd < d < 0 + Dr Sd
(avec par exemple Dr = 2,58
pour r% = 1%)
Comparaison
de deux distributions
Test du c2
On utilise ce test pour juger
De l’adéquation d’une population à une distribution
type (exemple loi de poisson)
De l’homogénéité de 2 populations soupçonnées de
suivre une même loi
De l’indépendance de deux populations
|
Méthode On répartit les valeurs de
l'échantillon (de taille N) dans k classes
distinctes et on calcule les effectifs de ces classes. Si l’on regroupe
certaines classes pour les doter d’un effectif plus important, k diminue en conséquence. On calcule La statistique Le degré de liberté (d) de la variable soumise au test (oi) est obtenu en soustrayant à k le nombre de relations entre les k valeurs qui ont été utilisées dans
le paramétrage de la loi de référence. Par exemple si on a une
relation de type Σ oi = n (loi B(n,p))
le degré de liberté devient k – 1 Si, de plus on a eu besoin
de calculer la moyenne m des oi pour tester l’adéquation à la loi
B(n,p) (p déduit de m) ou P(m) (m paramètre de la loi de Poisson) le degré de
liberté deviendra k – 2. La table donne, pour d degrés de libertés, une fonction de répartition de En situant |
|
|
||||||||||||||||||||||||
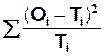
|
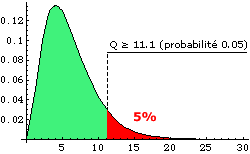
Exemple On a lancé un dé 90 fois et
on a obtenu les issues 1 à 6 (k=6) avec les effectifs suivants: 12, 16, 20,
11, 13, 18. Si le dé n'est pas pipé (notre hypothèse), on attend comme
effectifs moyens théoriques 15 pour toutes les issues. On pose
Pour k-1=5 degrés de
liberté on trouve dans la table Q entre les valeurs
Ce qui signifie que la
probabilité pour Q d’être dépassé est un peu supérieure à 50% . L’adéquation de la loi à la série n’est pas fameuse. |
|
Exemples :
1
Les Oi sont les effectifs des
classes pour lesquelles X = Xi .
On a une série de 7 valeurs Oi avec pour seule relation Σ Oi
= 100.
Donc d = 7 – 1 = 6 degrés de
liberté.
On nous demande si on peut
ajuster cette série par une loi B(100 ; 0,04).
On calcule les 7 effectifs
théoriques correspondants Ti .
Puis ![]() . On trouve
. On trouve ![]() = 0,45
= 0,45
Dans la table pour d = 6 on lit P(![]() > 2,2) = 0,9
> 2,2) = 0,9
Donc à fortiori P(![]() > 0,45) > 0,9
> 0,45) > 0,9
On en déduit qu’on peut sans
problème ajuster la série par la loi B(100 ; 0,04).
2
Pour la même série, on
calcule la moyenne m de
l’échantillon.
m = 3,9 pour un effectif de 100.
On nous demande si l’on peut
ajuster la série par la loi B(100 ; 0,39)
Cette fois on a 2 relations
entre les paramètres de la loi et les données:
Σ oi = 100
et 0,39 = (Σ oiXi ) / 100
Donc il faudra regarder dans
la table de d =7 – 2 = 5 degrés de
liberté.
Où l’on trouvera P(![]() > 1,6) = 0,9
> 1,6) = 0,9
Et comme nous calculerons un ![]() de 0,4 nous en
déduirons que là aussi l’ajustement est acceptable.
de 0,4 nous en
déduirons que là aussi l’ajustement est acceptable.
3
Puis pour la même série on
peut tenter l’ajustement par une loi normale.
N(m , s) .
Pour cela il faut calculer s ce
qui nous donne une 3e relation aux côtés de
Σ oi = 100 et 0,39
= (Σ oiXi ) / 100
On aura donc d = 7 – 3 = 4 degrés de libertés.
Dans la table on trouvera P(![]() > 1,06) = 0,9
> 1,06) = 0,9
On voit que plus l’ajustement
est ambitieux (accroissement du nombre
de paramètres exigés par la loi) plus l’exigence en ![]() est sévère (plus le
est sévère (plus le ![]() doit être faible)
doit être faible)